Gro Intelligence Data Hackathon
Last weekend, Gro Intelligence hosted their first hackathon in Nairobi at their office space.

The hackathon was focussed around data processing, specifically data from the USDA NASS (National Agricultural Statistics Service). The aim of the hackathon was to create a (Python) application that would download county crop data from the service, based on the dates provided by the user, and store it in a PostgreSQL table (also specified by the user).
For example, if a user specified a start date of 2005 and 2015, the application should fetch data from the NASS service, either through the API (http://quickstats.nass.usda.gov/api/), or from the data dumps provided (ftp://ftp.nass.usda.gov/quickstats/), and store it in a table (called facts_data).
Sounds easy, right?
Well, consider this:
- The API can only return a maximum of 50,000 records at a go
- The data files, when decompressed, occupy several GB of disk space
We had 2 options, figure out how to use the API with the limitation, or parse the data files. I decided to go with the API option; mainly because I could be more granular with my data fetching/processing, depending on the user queries.
However, I still had to get around the record limit, since some annual data, especially from year 2000+, was averaging 900k. The good thing is that the API provided a get_counts endpoint, which you can use to tell you how many records your current filters will return.
The approach I decided on was 2 fold:
- The main app would handle fetching of the data within API limits, and storing it in easy to process chunks as JSON files;
- A second process, spawned by the first, would process the JSON files downloaded - by parsing the JSON, extracting the required fields, and storing the data in the database. It also deletes the JSON file to make sure we don’t eat up too much (unnecessary) disk space
The first part of the app I created validated the dates input by the user, and built the query that would be used for the request.
Next, the “file processing” process is spawned. I used the subprocess command for this. It runs the file_processor.py file from within the virtualenv we’re using from the app:
# ...
# file_proc_command defined
# ...
subprocess.Popen(file_proc_command, shell=True, close_fds=True)
# more codeSetting shell=True ensured the command would run as if it was in a real shell. (Yes, I know it’s not advisable to use this, but it was a hackathon, right? ;)
The close_fds=True makes sure that the spawned process won’t be killed off when the main process stops.
The file processor is set to run as an asynchronous process (using asyncore.loop()). It runs as long as:
- The main process is still running (I create a pid file once I start the main process, delete once it’s done)
- There are JSON files to be processed
Finally, the script will start fetching the data from the API. A few points around the processing:
- If all the data, based on the user’s query, will amount to less than 50k records, we’ll fetch the data in a single batch
- If the data spans multiple years, we’ll fetch it in annual batches
- If the annual data exceeds 50k, we’ll fetch by state
- Finally, if state data will exceed the limit, we’ll go further and fetch by agricultural county
My main challenges when working on this were memory or CPU exhaustion on the server. My measly 512 MB vagrant box was definitely up to the challenge, I finally had good use for my Linode box.
I had to keep track of how many records I was holding in memory at any one point, and I would write them out to the JSON file once they reached a given limit. This ensured memory usage was kept at bay.
Here are some stats from my server during the times I was running the script. The CPU spikes represent the processing of the JSON files.
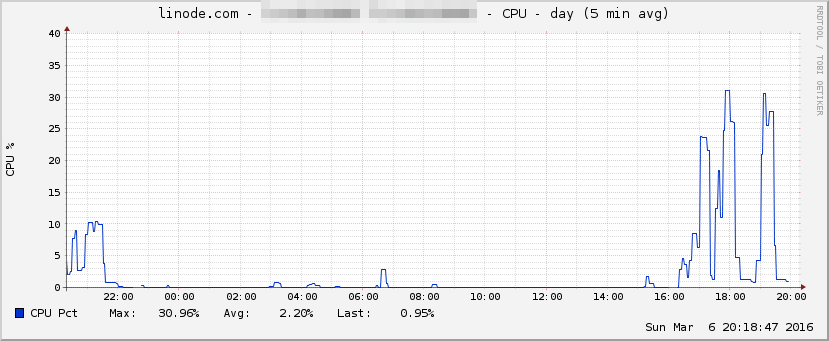
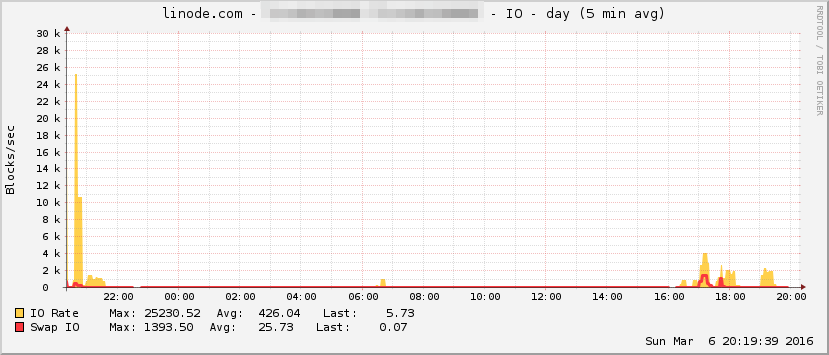
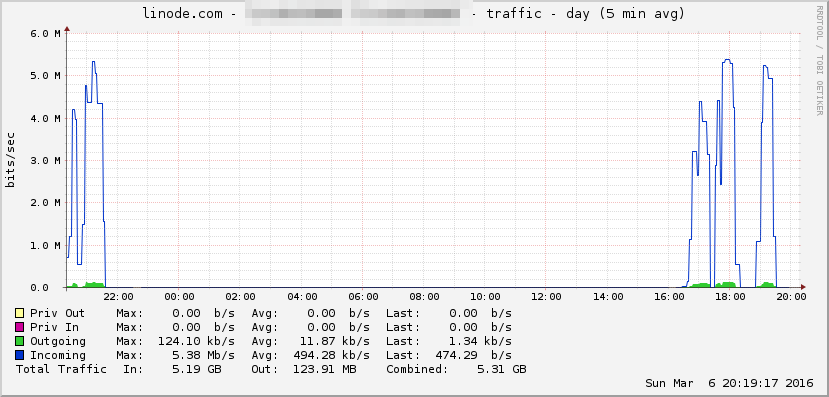
In a production environment, caching would be a major improvement to the application. For example, cache some of the annual data, so that when different users query overlapping years, time taken for processing would be much less, since the biggest bottleneck was querying the data from the API.
You can check out what I worked on here: https://github.com/muya/gro-hackathon; I’m looking forward to know whose solution took the prize!
Overall, the hackathon was very intense; definitely a good way to spend a weekend. It was a little unusual to work on the projects solo, but still fun all the same.
PS: Gro made sure we were well fed during the event on Saturday, thumbs up for that!